Conceptos y arquitectura de los sistemas de bases de datos
La arquitectura de los paquetes DBMS ha evolucionado desde los antiguos sistemas monolíticos, en los que todo el paquete de software DBMS era un sistema integrado, hasta los modernos paquetes DBMS con un diseño modular y una arquitectura de sistema cliente/servidor.
Esta evolución es reflejo de las tendencias en computación, donde los grandes computadores mainframe centralizados se han sustituido por cientos de estaciones de trabajo distribuidas y computadores personales conectados a través de redes de comunicaciones a distintos tipos de servidores (servidores web, servidores de bases de datos, servidores de archivos, servidores de aplicaciones, etc.).
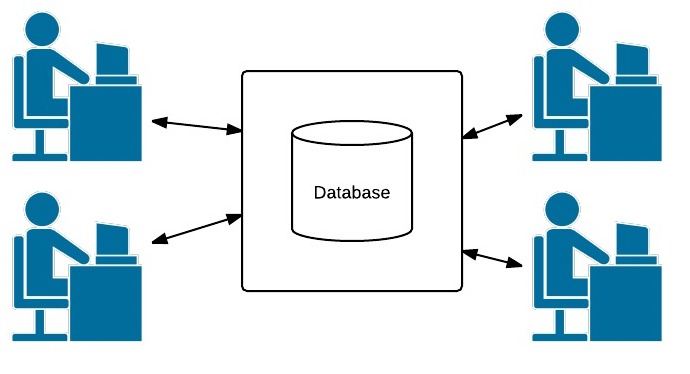
En una arquitectura DBMS cliente/servidor básica, la funcionalidad del sistema se distribuye entre dos tipos de módulos.Un módulo cliente se diseña normalmente para que se pueda ejecutar en la estación de trabajo de un usuario o en un computador personal. Normalmente, las aplicaciones y las interfaces de usuario que acceden a las bases de datos se ejecutan en el módulo cliente. Por tanto, el módulo cliente manipula la interacción del usuario y proporciona interfaces amigables para el usuario, como formularios o GUls basadas en menús.
El otro tipo de módulo, denominado módulo servidor, manipula normalmente el almacenamiento de los datos, el acceso, la búsqueda y otras funciones.
Esta evolución es reflejo de las tendencias en computación, donde los grandes computadores mainframe centralizados se han sustituido por cientos de estaciones de trabajo distribuidas y computadores personales conectados a través de redes de comunicaciones a distintos tipos de servidores (servidores web, servidores de bases de datos, servidores de archivos, servidores de aplicaciones, etc.).
En una arquitectura DBMS cliente/servidor básica, la funcionalidad del sistema se distribuye entre dos tipos de módulos.Un módulo cliente se diseña normalmente para que se pueda ejecutar en la estación de trabajo de un usuario o en un computador personal. Normalmente, las aplicaciones y las interfaces de usuario que acceden a las bases de datos se ejecutan en el módulo cliente. Por tanto, el módulo cliente manipula la interacción del usuario y proporciona interfaces amigables para el usuario, como formularios o GUls basadas en menús.
El otro tipo de módulo, denominado módulo servidor, manipula normalmente el almacenamiento de los datos, el acceso, la búsqueda y otras funciones.
Modelos de datos, esquemas e instancias
Una característica fundamental de la metodología de bases de datos es que ofrece algún nivel de abstracción
de los datos. La abstracción de datos se refiere generalmente a la supresión de detalles de la organización y
el almacenamiento de datos y a la relevancia de las características fundamentales para un conocimiento mejorado
de los datos.
Una de las características principales de la metodología de bases de datos es soportar la abstracción
de datos para que diferentes usuarios puedan percibir esos datos con el nivel de detalle que prefieren.
Un modelo de datos (colección de conceptos que se pueden utilizar para describir la estructura de una base de datos) proporciona los medios necesarios para conseguir esa abstracción.
Por estructura de una base de datos nos referimos a los tipos de datos, relaciones y restricciones que deben mantenerse para los datos.
La mayoría de modelos de datos también incluyen un conjunto de operaciones básicas para especificar las recuperaciones y actualizaciones en la base de datos.
Un modelo de datos (colección de conceptos que se pueden utilizar para describir la estructura de una base de datos) proporciona los medios necesarios para conseguir esa abstracción.
Por estructura de una base de datos nos referimos a los tipos de datos, relaciones y restricciones que deben mantenerse para los datos.
La mayoría de modelos de datos también incluyen un conjunto de operaciones básicas para especificar las recuperaciones y actualizaciones en la base de datos.
Categorías de modelos de datos
Se han propuesto muchos modelos de datos, que podemos clasificar conforme a los tipos de conceptos que
utilizan para describir la estructura de la base de datos.
Los modelos de datos de alto nivel o conceptuales
ofrecen conceptos muy cercanos a como muchos usuarios perciben los datos, mientras que los modelos de
datos de bajo nivel o físicos ofrecen conceptos que describen los detalles de cómo se almacenan los datos en
el computador.
Los conceptos ofrecidos por los modelos de datos de bajo nivel están pensados principalmente
para los especialistas en computadores, no para los usuarios finales normales.
Entre estos dos extremos hay una clase de modelos de datos representativos (o de implementación), que ofrecen conceptos que los usuarios finales pueden entender pero que no están demasiado alejados de cómo se organizan los datos dentro del computador. Los modelos de datos representativos ocultan algunos detalles relativos al almacenamiento de los datos, pero pueden implementarse directamente en un computador.
Entre estos dos extremos hay una clase de modelos de datos representativos (o de implementación), que ofrecen conceptos que los usuarios finales pueden entender pero que no están demasiado alejados de cómo se organizan los datos dentro del computador. Los modelos de datos representativos ocultan algunos detalles relativos al almacenamiento de los datos, pero pueden implementarse directamente en un computador.
Los modelos de datos conceptuales utilizan conceptos como entidades, atributos y relaciones. Una entidad
representa un objeto o concepto del mundo real, como un empleado o un proyecto que se describe en la base
de datos.
Un atributo representa alguna propiedad de interés que describe a una entidad, como, por ejemplo, el nombre o el salario de un empleado. Una relación entre dos o más entidades representa una asociación entre dos o más entidades; por ejemplo, una relación de trabajo entre un empleado y un proyecto.
Un atributo representa alguna propiedad de interés que describe a una entidad, como, por ejemplo, el nombre o el salario de un empleado. Una relación entre dos o más entidades representa una asociación entre dos o más entidades; por ejemplo, una relación de trabajo entre un empleado y un proyecto.
Esquemas, instancias y estado de la base de datos
En cualquier modelo de datos es importante distinguir entre la descripción de la base de datos y la misma base
de datos. La descripción de una base de datos se denomina esquema de la base de datos, que se especifica
durante la fase de diseño y no se espera que cambie con frecuencia.
La mayoría de los modelos de datos tienen ciertas convenciones para la visualización de los esquemas a modo de diagramas.
Un esquema visualizado se denomina diagrama del esquema. La Figura muestra un diagrama del esquema para una base de datos, el diagrama muestra la estructura de cada tipo de registro, pero no las instancias reales de los registros. A cada objeto del esquema (como ESTUDIANTE o CURSO) lo denominamos estructura de esquema.
La mayoría de los modelos de datos tienen ciertas convenciones para la visualización de los esquemas a modo de diagramas.
Un esquema visualizado se denomina diagrama del esquema. La Figura muestra un diagrama del esquema para una base de datos, el diagrama muestra la estructura de cada tipo de registro, pero no las instancias reales de los registros. A cada objeto del esquema (como ESTUDIANTE o CURSO) lo denominamos estructura de esquema.

Un diagrama del esquema sólo muestra algunos aspectos de un esquema, como los nombres de los tipos de
registros y los elementos de datos, y algunos tipos de restricciones. Otros aspectos no se especifican; por ejemplo, la Figura no muestra los tipos de datos de cada elemento de datos, ni las relaciones entre los distintos
archivos. En los diagramas de esquemas no se representan muchos de los tipos de restricciones. Una restricción
como, por ejemplo, "los estudiantes que se especializan en ciencias de la computación deben terminal'
CCJ3lO antes de finalizar su curso de segundo año", es muy difícil de representar.
Los datos reales de una base de datos pueden cambiar con mucha frecuencia. Por ejemplo, la base de datos de la Figura cambia cada vez que se añade un estudiante o se introduce una calificación nueva. Los datos de la base de datos en un momento concreto se denominan estado de la base de datos o Sllupshot (captura).
También reciben el nombre de conjunto actual de ocurrencias o instancias de la base de datos. En un estado dado de la base de datos, cada estructura de esquema tiene su propio conjunto actual de instancias; por ejemplo, la construcción ESTUDIANTE contendrá el conjunto de entidades estudiante individuales (registros) como sus instancias. Es posible construir muchos estados de la base de datos para que se correspondan con un esquema de bases de datos particular. Cada vez que se inserta o borra un registro, o cambia el valor de un elemento de datos de un registro, cambia el estado de la base de datos por otro.
Los datos reales de una base de datos pueden cambiar con mucha frecuencia. Por ejemplo, la base de datos de la Figura cambia cada vez que se añade un estudiante o se introduce una calificación nueva. Los datos de la base de datos en un momento concreto se denominan estado de la base de datos o Sllupshot (captura).
También reciben el nombre de conjunto actual de ocurrencias o instancias de la base de datos. En un estado dado de la base de datos, cada estructura de esquema tiene su propio conjunto actual de instancias; por ejemplo, la construcción ESTUDIANTE contendrá el conjunto de entidades estudiante individuales (registros) como sus instancias. Es posible construir muchos estados de la base de datos para que se correspondan con un esquema de bases de datos particular. Cada vez que se inserta o borra un registro, o cambia el valor de un elemento de datos de un registro, cambia el estado de la base de datos por otro.
Arquitectura de tres esquemas e independencia de los datos
Tres de las cuatro importantes características de la metodología de bases de datos son:
(l) aislamiento de los programas y los datos (independencia programa-datos y programaoperación),
(2) soporte de varias vistas de usuario y
(3) uso de un catálogo para almacenar la descripción de la base de datos (esquema).
(l) aislamiento de los programas y los datos (independencia programa-datos y programaoperación),
(2) soporte de varias vistas de usuario y
(3) uso de un catálogo para almacenar la descripción de la base de datos (esquema).
Arquitectura de tres esquemas
El objetivo de la arquitectura de tres esquemas, ilustrada en la Figura, es separar las aplicaciones de usuario
y las bases de datos fisicas.
En esta arquitectura se pueden definir esquemas en los siguientes tres niveles:
En esta arquitectura se pueden definir esquemas en los siguientes tres niveles:
- El nivel interno tiene un esquema interno, que describe la estructura de almacenamiento físico de la base de datos. El esquema interno utiliza un modelo de datos fisico y describe todos los detalles del almacenamiento de datos y las rutas de acceso a la base de datos.
- El nivel conceptual tiene un esquema conceptual, que describe la estructura de toda la base de
datos para una comunidad de usuarios.
El esquema conceptual oculta los detalles de las estructuras de almacenamiento físico y se concentra en describir las entidades, los tipos de datos, las relaciones, las operaciones de los usuarios y las restricciones. Normalmente, el esquema conceptual se describe con un modelo de datos representativo cuando se implementa un sistema de bases de datos.
Este esquema conceptual de implementación se basa a menudo en un diseño de esquema conceptual en un modelo de datos de alto nivel. - El nivel de vista o externo incluye una cierta cantidad de esquemas externos o vistas de usuario. Un esquema externo describe la parte de la base de datos en la que un grupo de usuarios en particular está interesado y le oculta el resto de la base de datos. Como en el caso anterior, cada esquema externo se implementa normalmente mediante un modelo de datos representativo, posiblemente basado en un diseño de esquema externo de un modelo de datos de alto nivel.

La arquitectura de tres esquemas es una buena herramienta con la que el usuario puede visualizar los niveles del esquema de un sistema de bases de datos. La mayoría de los DBMSs no separan completa y explícitamente los tres niveles, pero soportan esta arquitectura en cierta medida.
Independencia de los datos
La arquitectura de tres esquemas se puede utilizar para explicar el concepto de independencia de los datos,
que puede definirse como la capacidad de cambiar el esquema en un nivel de un sistema de bases de datos sin
tener que cambiar el esquema en el siguiente nivel más alto. Se pueden definir dos tipos de independencia de
datos:
- Independencia lógica de datos. Es la capacidad de cambiar el esquema conceptual sin tener que cambiar los esquemas externos o los programas de aplicación. Es posible cambiar el esquema conceptual para expandir la base de datos (añadiendo un tipo de registro o un elemento de datos), para cambiar las restricciones o para reducir la base de datos (eliminando un tipo de registro o un elemento de datos). En el último caso, no deben verse afectados los esquemas externos que sólo se refieren a los datos restantes.
- Independencia física de datos. Es la capacidad de cambiar el esquema interno sin que haya que cambiar el esquema conceptual. Por tanto, tampoco es necesario cambiar los esquemas externos.